ATi显卡命名的规则

ATi显卡命名规律
和nVIDIA一样,ATi显卡的命名也按照了一定的规律进行,对相同核心的不同型号显卡,以不同的命名规则区分开,以方便消费群体识别好显卡之间的级别,下面我们就说说ATi常见的命名规律。
XTX > XT > XL/GTO > Pro/GT > SE
XTX:ATI系列中 高端显卡型号的后缀,如:1800XTX,1900XTX。这个后缀编号都是当时 高端的ATi显卡所配有的。
XT:这个编号比较有意思,ATi和nVIDIA都采用这个编号,但两者表达的意义却不同,用户需要区分开。
在ATi方面,XT是代表了顶级显卡的型号,一般就运行频率稍低于XTX,XT与XTX的关系就像nVIDIA中GTX和Ultra的一样。我们知道的高端显卡就有Radeon X1950XT、Radeon HD 2900XT,它们都采用了XT这个后缀。
而在nVIDIA方面,XT却是代表了简化版,比标准版更低,如GeForce 5600XT,消费者需要区分开来。但在以后的代数中,nVIDIA也很少用到XT这个后缀命名。
XL:用于ATi高端显卡系列的后缀,级别比顶级级别的XT低,主要表现在频率和管线上有所缩水。
GTO:是ATi较为特殊的命名后缀,也是用于中高端显卡系列,其意义就有点类似于nVIDIA的“GS”一样,比XL级别稍低。
Pro/GT:Pro和GT的级别都要低于XT,一般来说,采用同一核心代号的ATi显卡,Pro的级别要稍高于GT,如X1950Pro和X1950GT,主要表现在运行频率上,Pro要高于GT。但我们需要区分清楚,当采用不同核心代号的ATi显卡时,GT的级别是可以高于Pro的,如X1650GT和X1650Pro,单从命名上看貌似X1650Pro要高级于X1650GT,但实际却是相反的,X1650Pro采用了RV530的显示核心,要低级于1650GT采用的RV560,因此X1650Pro的级别要低于X1650GT。
SE:全名为“Special Edition”(特殊版),主要用于ATi中低端显卡系列的后缀。采用这个后缀的显卡在管线上会有所缩减。
以上是过去ATi显卡型号中常见的后缀命名规则,在Radeon HD 3000系列之前,我们都可以通过上面的方法基本判断出采用了同一显示核心ATi显卡的级别,但到了Radeon HD 3000系列,这种容易被混乱的命名后缀方法被除去了,改而更加直观的命名方法,下面我们来介绍ATi这种新的命名法则。
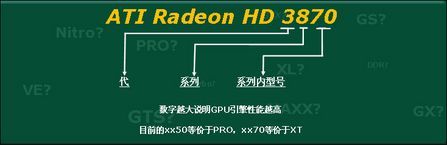
ATi自Radeon HD 3000开始采用了新的命名方式
如上图所示,ATi自Radeon HD 3000系列开始采用了新的命名方法,拿Radeon HD 3870为例,其中“3”代表了显卡代数、“8”代表了系列,而“70”则代表了显卡的系列内型号,数字越大代表的级别就越高。这种命名方式比起过去的更为直观更容易区分开,无疑更有利于消费者判断。
ATi的辉煌:DX9时代ATI 3:1黄金架构
目前无论是DirectX10、Vista操作系统还是完整支持DirectX10的游戏都只是起步阶段。Crysis也仅仅是部分特效才会用到DirectX10的特效,这正如一个复杂的DirectX9.0C游戏目前会用到前代DirectX特效一样,普通不过。在R600尚未来临之前, ATI觉得一块性能优秀的DirectX9.0C显卡相当重要。Unified shader架构让资源的分配更为合理,而ATI的3:1架构则是大幅暴力的增加pixel shader去迎合复杂游戏的需求,因而两者的指导思想相近。
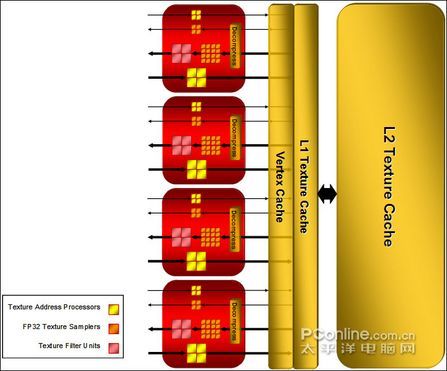
ATI在X1000系列的Pixel Shader Engine首次引入了Ultra-Threading Dispatch Processor(超级线程分派处理器),超级线程分派处理器具备调度/控制逻辑,R520 多能够同时处理512个并行的线程。在当今显卡架构设计中,多线程思想是相当重要的。多线程能够使得GPU的象素处理核心在等待请求的同时,还能够处理其他的请求。配合SM3.0的加速流控制,消灭纹理等待和减少渲染等待,大大提高性能。当然RadeonX1900系列(R580)也支持SM3.0和Ultra-Threading Dispatch Processor(超级线程分派处理器)。
R580是R520的火力加强版,更加证实了R580才是ATI先前所说的“完美版本”。R580和R520均支持的Ringbus环形内存通路。
无论是ATI还是nVIDIA,他们都意识到像素渲染已经成为当今游戏引擎的一个性能瓶颈,自从微软在2001年在DirectX8.0的API中引入了可编程渲染引擎以后,渲染处理开始在游戏中变得非常普遍,而渲染指令的复杂程度也在以每年1.8倍的速度增长,我们可以看到在2004年,随着真正的DirectX9.0游戏,Facry和Halflife2的引入,游戏引擎对像素渲染的要求一下子高了很多。
当然像素处理引擎的渲染指令包括从显存中拾取数据的纹理操作和完成数学变化的渲染处理操作。实际上这两种渲染指令的使用比例决定者图形芯片像素处理引擎的组成。ATI认为大部分的像素处理都是双线过滤操作或者从整数纹理中进行点取样,并没有多少纹理查找的过程。纹理操作过多依赖于显存容量跟带宽这些外界因素,而算术处理操作则不同,它的处理能力大多数场合取决于像素处理器集成的像素渲染单元的数量。理论上通过相应的约束参数纹理操作生成像素算术纹理,可以降低纹理操作对外界因素的制约。
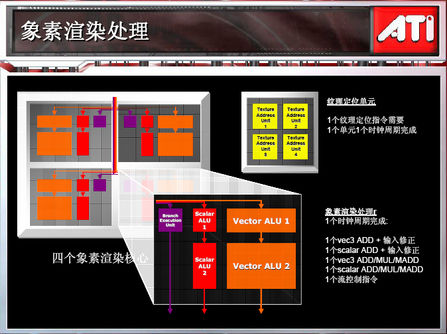
(R580拥有三倍于R520的像素渲染单元)
传统的管线概念(Pipeline)中,像素渲染单元(Pixel Shader)跟Pipeline数目相同,象NVIDIA的G70图形就是这么一个概念;但是ATI在全新的R580图形芯片中,稍微修正了像素渲染单元跟Pipeline的关系。RadeonX1900需要重点强调的地方在于,R580图形芯片拥有16条传统的像素管线(Pixel Pipeline),但是却拥有48个像素渲染单元和16个纹理单元,算术处理能力是以前旗舰级GPU的3倍,在晶体管数量只增加20%的情况下,渲染能力理论上增加了200%,像素渲染单元跟纹理单元的比例是3:1。实际上ATI在当时的中端显卡RadeonX1600上也使用了这种比例关系,形象点来说RadeonX1900似乎是由四个RadeonX1600组成的旗舰代表。
RadeonX1950GT同样也是ATI 3:1黄金架构的产品, 拥有36 Pixel shader和8个顶点和纹理单元。在ATi的R600来临之前,通过这点提高显卡核心的整体渲染效率,无疑得到了立杆见影的作效。
即便ATi在R580中引入了1:3的黄金渲染架构,但传统的渲染架构还是存在弊端的,在目前许多新的大型3D游戏中,许多独立渲染的场景由大量多边形组成,对GPU的Vertex Shader(顶点着色器)要求很大,而这时相对来说,并不需要太多的像素渲染操作,这样便会出现像素渲染单元被闲置,而顶点着色引擎却处于不堪重荷的状态,为了解决这一问题,ATi开发除了统一超标量着色架构(Unified Superscalar Shader Architecture)的R600系列。
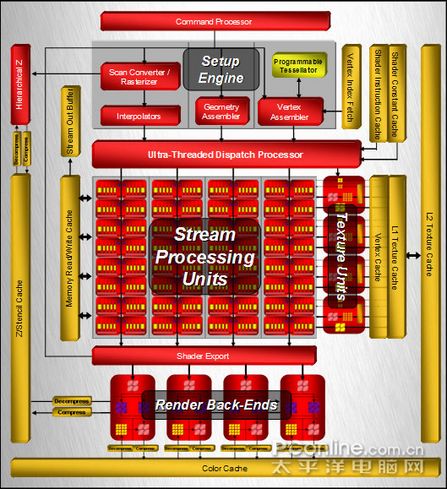
得益于80nm核心工艺制程的帮助,Radeon HD 2900XT显卡终于摆脱传统“管线”概念的束缚,采用更为高效的统一超标量着色架构(Unified Superscalar Shader Architecture),内置了高达320个流处理器单元(64*5),全面支持Microsoft DirectX 10.0和Shader Model 4.0,能同时兼容DirectX 10和DirectX 9 与OpenGL等引擎开发的3D游戏。下面是有关Radeon HD 2900XT显卡的核心架构体系图。
Radeon HD 2900XT 核心架构图示
DirectX 10 大的革新就是统一渲染架构(Unified Shader Architecture)。目前的GPU架构还是沿用的分离式渲染架构,此前NVIDIA的G71和ATI的R580都是采用这样的架构,顶点渲染和像素渲染各自独立进行,而且一旦当架构确定下来,顶点和像素shader单元的比例就会固定下来。不过分离式渲染架构设计更为简便而且经验丰富,例如NVIDIA的NV40发成到后来的G70/G71,又或者是R420到R580,性能都得到显而易见的提升。
微软认为这种分离渲染架构不够灵活,不同的GPU,其像素渲染单元和顶点渲染单元的比例不一样,大大限制了开发人员自由发挥的空间。不同的应用程序和游戏对像素渲染和顶点渲染的需求不一样,导致GPU的运算资源得不到充分利用。微软在DirectX 10中提出了统一渲染架构,在通用和独立的shader单元中可以执行不同的shader程序,包括vertex、pixel和在DirectX 10中首次提出的geomery shader。而且随着这些通用独立的shader单元功能的不断完善,日后有望执行更多的shader程序,例如物理效果。
虽然ATi的R600和nVIDIA的G80同样是支持DirectX 10的显卡,但它们之间是有着本质的不同的,nVIDIA在其统一渲染架构中,通过Shader/核心频率异步的方式,使其Shader单元以高于核心频率两倍以上的速度运行,从而获得了更高的渲染效率。ATi在其统一超标量着色架构中,宣称R600拥有320个流处理单元,但准确来说,Radeon HD 2900XT是拥有64个流处理器,而每一个流处理器都配于5个1D逻辑计算器,因而ATi便宣称Radeon HD 2900XT拥有320个流处理器,这点做法和当初RV580有点类似,通过1:3的渲染管线和渲染单元的比例,大幅度的增加了显卡的渲染单元。
Radeon HD 2900XT 核心架构图示
DX9末代皇者:Radeon X1900系列
从前面介绍到,自R580开始,ATi就将1:3的黄金象素渲染规格划入其中、高端产品中,通过这种“暴力”方法使得显卡得到了更大幅度的性能提升,而作为DX9末代的代表,Radeon X1950GT相信没有人会忘记,即使在今天,这款显卡还是能够坚守在大多数DX9游戏面前的,下面我们来介绍这个ATi的末代DX9高端家族——RadeonX1900系列
| | RadeonX
1900XTX | Radeon
X1900GT | Radeon
X1950Pro | |
| 晶体管数量 | 384M | 384M | 330M | |
| 核心代号 | R580 | R580 | RV570 | |
| 工艺制程 | TSMC 90nm | TSMC 90nm | TSMC 80nm | TSMC 80nm |
| 核心时钟频率 | 650MHz | 570MHz | 575MHz | 500MHz |
| 显存时钟频率 | 1550MHz | 1200MHz | 1380MHz | 1200MHz |
| 显存类型 | GDDR3 | GDDR3 | GDDR3 | GDDR3 |
| 显存位宽 | 256Bit | 256Bit | 256Bit | 256bit |
| 显存容量 | 512MB | 256MB | 256/512MB | 256MB |
| 像素管线数量 | 16 | 12 | 12 | |
| 像素渲染单元 | 48 | 36 | 36 | |
| 顶点着色器数量 | 8 | 8 | 8 | 8 |
| 支持DirectX版本 | 9.0C | 9.0C | 9.0C | 9.0C |
| 公版PCB | - | - | - | - |
| Vertex Shader版本 | 3.0 | 3.0 | 3.0 | 3.0 |
| Pixel Shader版本 | 3.0 | 3.0 | 3.0 | 3.0 |
| 接口总线 | PCIE | PCIE | PCIE | PCIE |
| 双卡互联技术 | CrossFire | CrossFire | CrossFire* | |
我们由以上数据可以看出,X1950GT实际上是X1950Pro的降频版。RadonX1950GT基于RV570LE(有一说法是RV570XL)图形核心,属于ATI 3:1黄金架构,拥有12条像素管线,却拥有36 Pixel shader、8个vertex shader和8个纹理单元,具备256bit显存位宽。更多的Pixel单元使X1950GT的画面质量更显丰富细腻,尽管NV通过提高7900GS的工作频率来提高性能,但由于7900GS不具备X1950所具备的HDR+AA,因此从多个游戏的表现中我们都可以看出,ATi X1950GT的画面质量不是NV的7900GS所能叫板的。